Introduction to Machine Learning in Production (1)
introudction
deeplearning.ai 에서 제공하는 ML-Ops 관련 강의 https://www.coursera.org/learn/introduction-to-machine-learning-in-production 를 들어보기로 했다.
이 내용은 과정의 Week 1 을 듣고 기억에 남는 부분들을 정리한 내용이다.
사용된 이미지들의 출처는 위의 강의의 영상 캡처이다.
contents
1. The Machine Learning Project Lifecycle
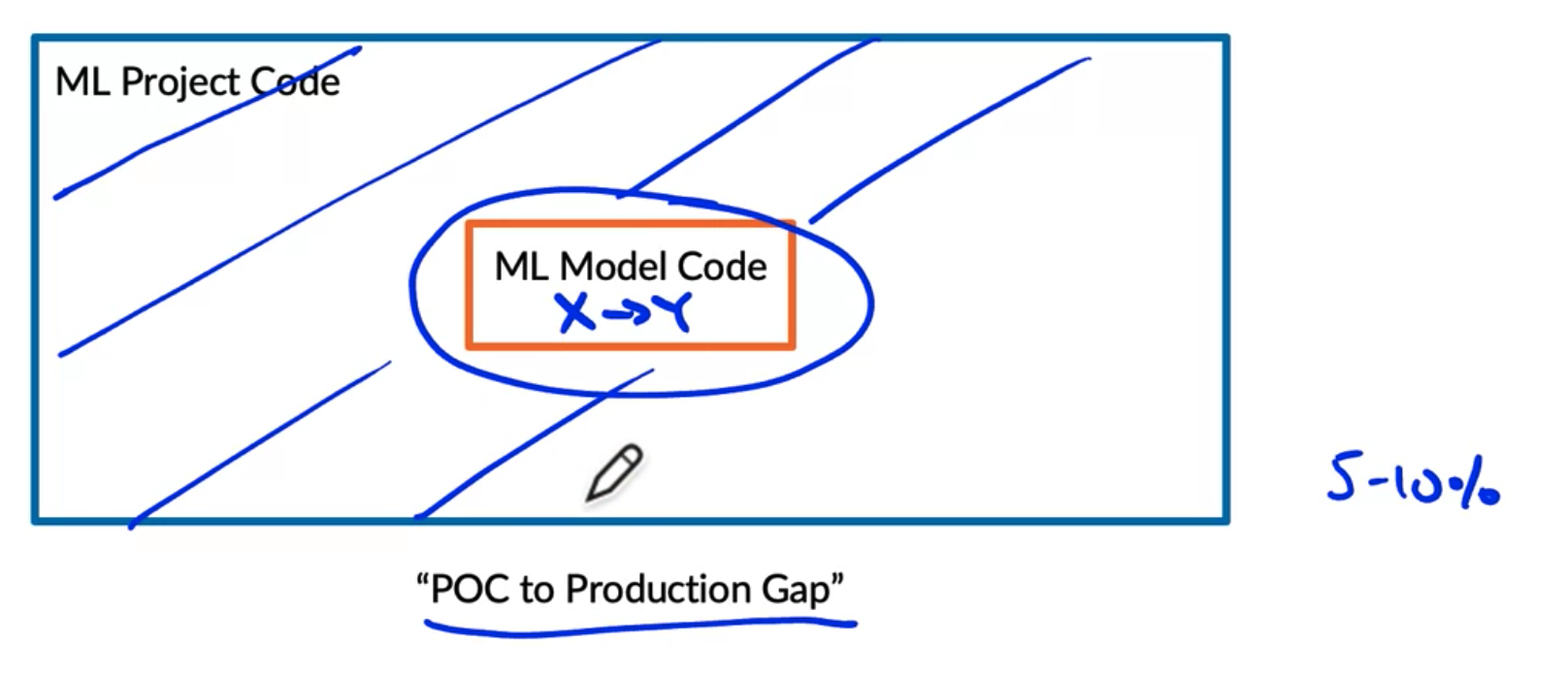
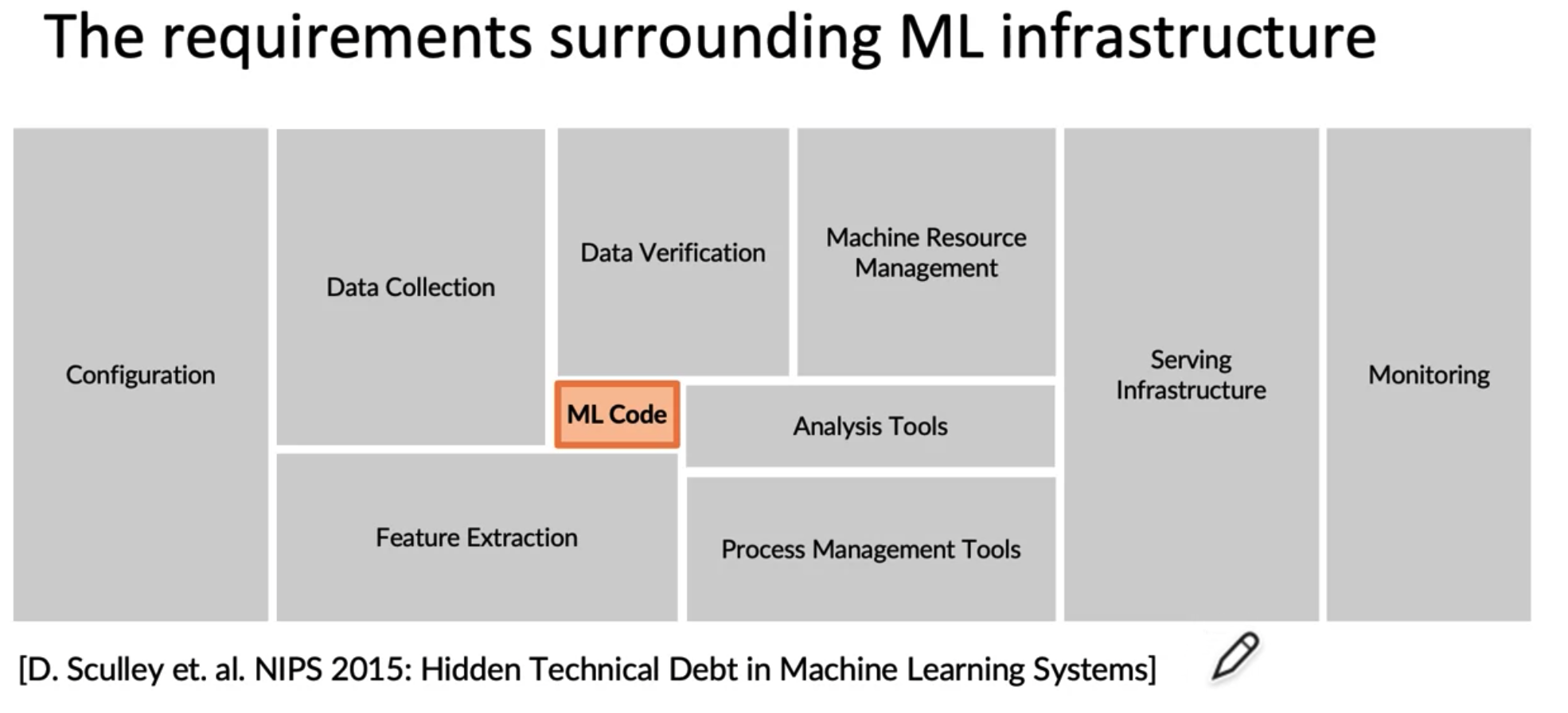
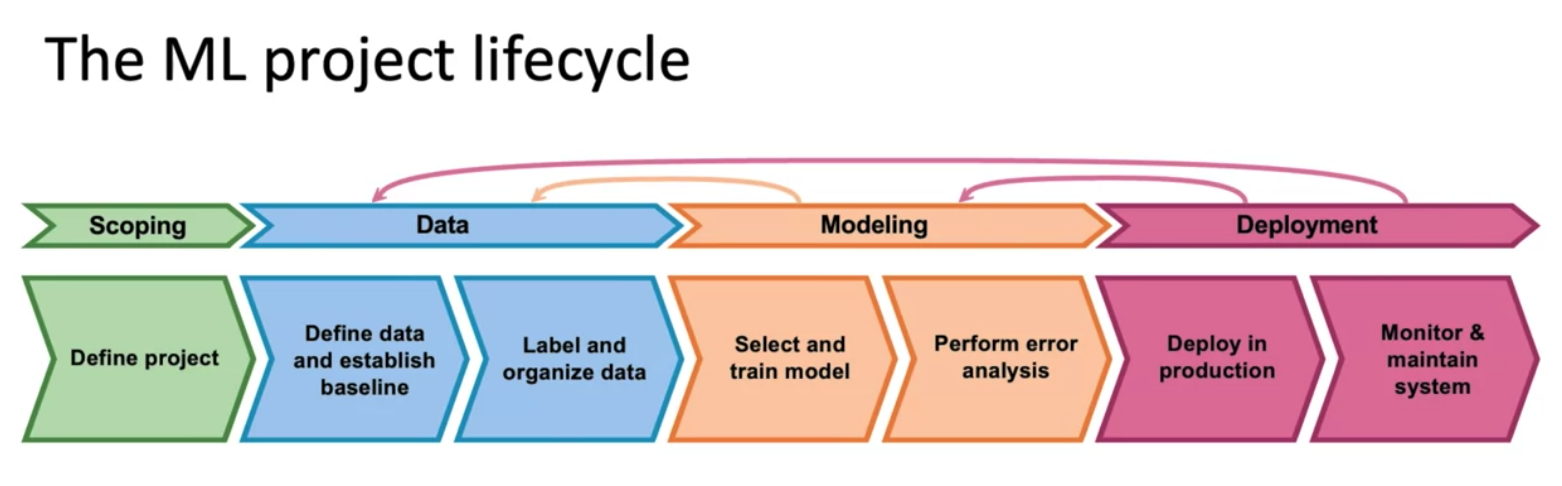
- 이 과정중에서 Modeling, Data Stage 로 돌아가서 모델을 재학습하거나 모델을 개선하거나 데이터를 더 많이 모으거나 하는 등의 반복적인 과정이 일어난다.
Data stage
- Define data
Um, today's weather,Um.. today's weather,Today's weather과 같이 한가지 데이터에 대해서 다양한 레이블링 방식이 이용될 수도 있는데, 일관적인 레이블링 방식 적용이 중요하다.
Modeling stage
Code(algorithm/model) + Hyperparameters + Data 합쳐서 ML Model 을 생성함
Research/Academia 에서는 Code + Hyperparameters 를 주로 변경하고 Product Team 에서는 Code 는 fixed 해두고 Hyperparameters / Data 를 변경하는 경향을 가진다.
ML System 에서 Code 를 변경하는 방법도 있지만, 대부분 Data 를 변경했을때 효과를 얻는다.
데이터를 많이 모으는게 중요하지만, error analysis 를 통해서 targeted data 를 모으는 식으로 더 효율적으로 할 수 있다.
Deployment stage
- Monitor & maintain system 과정에서 새로만든 모델이 젊은 사람들의 목소리에서 성능이 떨어진다는 것을 알게 됐다면, 데이터를 더 모아서 학습 시키는 방법을 택할 수 있다. (Concept drift / Data drift 에 대응)
MLOps is an emerging discipline, and comprises a set of tools and principles to support progress through the ML project lifecycle. 특히, Deployment/ Modeling/ Data 세가지 step 에 관여한다.
2. Deployment
Key Challenges
2가지 challenges 가 있는데, 그 중 한가지는 Concept Drift/ Data Drift 이고, 다른 한가지는 software engineering issues 이다.
Concept Drift/ Data Drift
예시 1: 스마트폰의 액정 스크래치를 확인하는 모델을 만들었는데, 공장의 조명이 변경되어서 데이터의 분포가 변경된 경우(distribution of the data changes).
예시 2(gradual change): ASR 모델을 만들었는데, 시간이 지나면서 데이터가 변경된다. 예를들어 더 좋은 스마트폰들을 쓰게되어서 audio input 의 형태가 변경됐다. 혹은 영어를 사용하는 사람들이 새로운 용어를 쓰게 되는 등..
예시 3(sudden shock): covid-19 이후로 credit card fraud detection system 이 제대로 동작하지 않게 되었다. 왜냐하면 사람들의 사용 패턴이 급격히 달라졌기 때문이다.
Concept drift 는 데이터 분포의 변경 보다는, 예를들어 fraud detection 이 온라인 구매 비중이 전보다 급격히 늘어서 fraud detecting 에 대한 concept 이 바뀐 상황으로 이해하면 될 것 같다. 강의에서 (x->y) 의 변경으로 설명한다. 집 크기에 따른 집값의 예에서, 집 크기는 변하지 않았지만 집 값이 많이 오르는 경우를 예로 들 수 있다.
Data drift 는 갑자기 사람들이 작은 집을 짓기 시작하거나 큰 집을 짓기 시작해서 데이터 분포가 바뀌는 상황을 의미한다.
Deployment 에서 중요한 부분은, concept drift 와 data drift 의 상황을 감지하고 이러한 변경에 대응할 수 있도록 하는것이다.
Software engineering issues
checklists:
- Realtime or Batch
- Cloud vs Edge/Browser
- 공장에서 사용하는 모델이, 인터넷 접근이 안된다고 공장을 멈출 수는 없으니, edge 에도 구성하는 편이다.
- Compute resources (CPU/GPU/memory)
- Latency, throughput(QPS, queries per second)
- 예를들어, 500ms 안에 결과를 처리해야되어서 speech recognition 은 300ms 안에 끝나야 된다.
- Logging
- Security and privacy
Deployment patterns
Common deployment cases
- New product/capability
- Autmoate/assist with manual task
- Replace previous ML System
적용 가능한 방식
- Shadowing (사람과 머신이 동시에 판단을 하지만, 데이터만 쌓고 머신의 판단을 실제로 사용하지는 않는 상태)
- Gradual ramp up with monitoring (새 버전으로 조금의 요청만 보내고, 나머지는 이전 버전으로 처리하며 모니터링함)
- Rollback(문제 생기면 여차하면 이전 버전으로 롤백함)
Canary deployment
- 판단 비중을 조금씩 늘려가는 방식
Blue green deployment
- Old/Blue version 과 New/Green version 을 동시에 갖고 앞단의 router 를 통해서 둘 중 하나로 쉽게 스위칭 할 수 있도록 한다.
Degress of automation
- Deployment 를 0/1 인 배포안됨/배포됨 의 상태로 보는게 아니라 활용 정도의 관점에서 보는것.
모델의 정확도에 따라 정도를 선택할 수 있다.
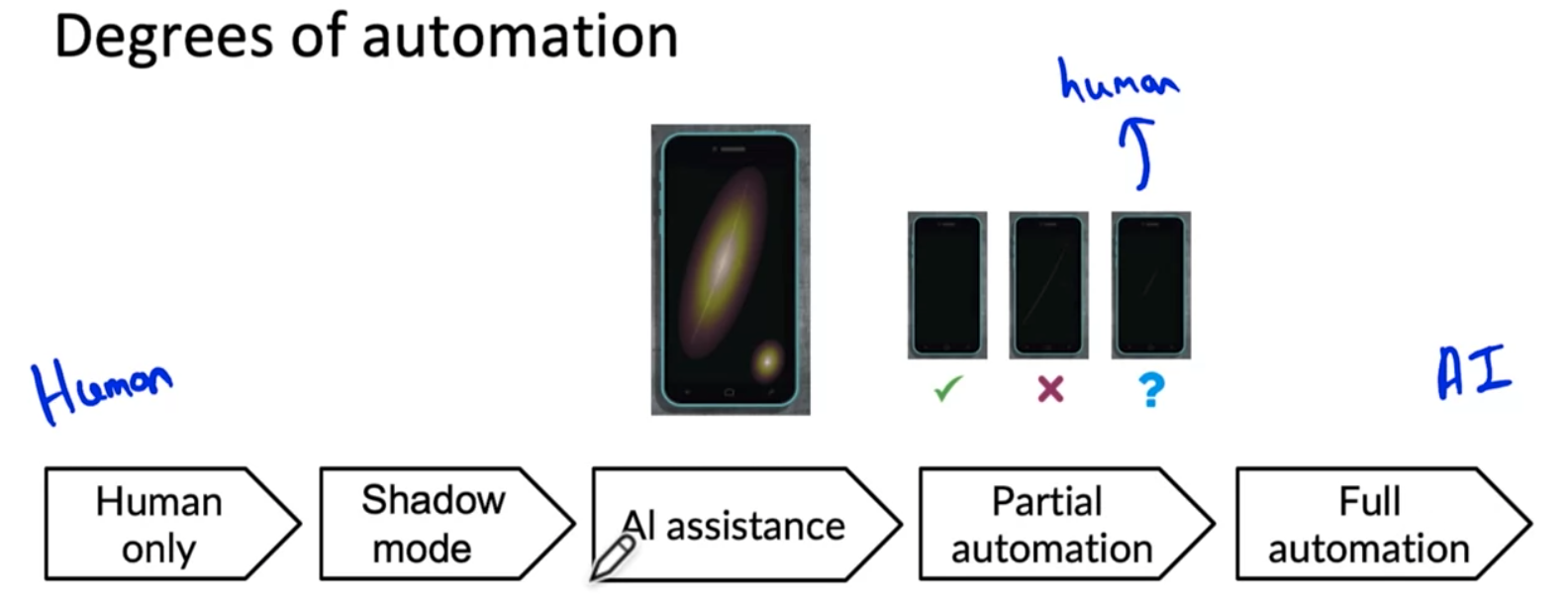
human in the loop 라는 얘기를 하는데, 인터넷 검색처럼 사람이 실시간으로 검색을 내려줄 수는 없는 상황이라면 full automation 이 필수이지만 공장에서 처럼 사람이 항상 있고 실시간으로 판단을 내릴 수 있는 상태라면 full-automation 보다 partial-automation 이 가장 좋은 선택일 수 있다고 한다.
Monitoring
Using a dashboard to track how it is doing overtime.
Server load, Fraction of non-null outputs(뭔가 잘못되고 있다는 지표, indication of something going wrong), Fraction of missing input values.
Team 과 함께 잘못될 수 있는 모든것에 대해 brainstorming 해보고 few metrics that will detect that problem 인 것들을 정해서 dashboard 를 만들어보는게 좋다.
Examples of metrics to track
- Software metrics:
- Memory, compute, latency, throughput, server load
- Input metrics:
- input distribution
Xchange 를 판단해볼 수 있는 지표들 (음성인식에서 예를들면 avg input length, avg input volume 과 같은). Data drift 와 같은 상황을 판단하기 위함
- input distribution
- Output metrics: (잘못된 결과를 준건 아닐까를 확인할 수 있는 지표, 모델의 성능이 degrading 된것은 아닐까?)
- number of times returning null
- number of times user redoes search
ML model 을 Experiment, Error analysis 의 과정을 통해서 반복적으로 개선하는것과 동일하게, Deployment/Monitoring 도 User Traffic 을 받고 계속 Performance analysis 를 통해서 반복적으로 deployment 와 monitoring 을 할 수 있다.
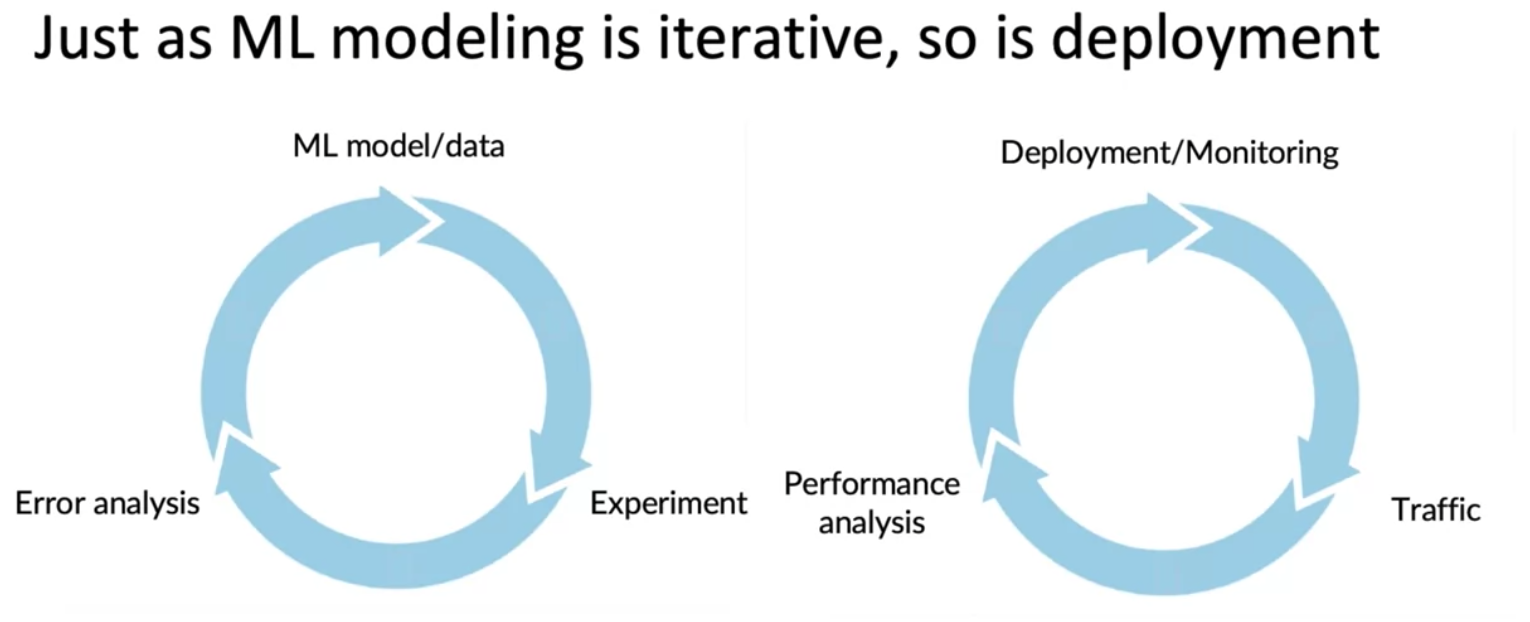
모든 소프트웨어들이 유지보수가 필요한것 처럼, 모델들도 유지보수가 필요하다.
수동으로 재학습 할수도 있고, 자동으로 재학습할수 있다.
Pipeline Monitoring
대부분의 ML system 은 단일 모델이 아닌, 여러 단계의 모델이 파이프라인으로 구성된다.
How quickly do metrics to monitor change?
- User data generally has slower drift.
- Enterprise data(B2B applications) can shift fast. (예를들어 스마트폰 공장에서 갑자기 새로운 액정을 사용하기로 결정했으면 데이터가 한번에 바뀔것이고, CEO 의 결정에 따라 크게 변경될 수도 있다)
Comments powered by Disqus.