Naver AI Now
introduction
Naver 에서 AI Now 라는 온라인 행사를 개최했고, 신청을 해서 보게 되었다. 아래는 각 세션들을 들으며 몇몇 키워드들, 내용들을 정리해봤다.
잘못 정리한 내용이 있을수도, 간혹 빈 부분이 있을수도 있지만, 개인적인 용도의, 개인적인 정리를 위함이라 필요에 의해 이후에 추가하거나, 계속 업데이트가 되지 않을 수도 있다.
네이버가 갖고있는 상당한 양의 한국어 데이터들을 Big AI 형태로 큰 모델을 생성했고, 이때 사용한 데이터는, 5600억 토큰의 한국어 데이터 (GPT-3 가 사용한 한국어 데이터의 6500배 수준이라고 한다)와 700페타플롭스? 의 슈퍼컴퓨터를 학습/인퍼런스에 이용한다고 하는데 아무튼 어마어마한 자본을 때려넣어 큰 모델을 만들었고, NLP 분야의 다양한 태스크 해결에 사용하고 있는것으로 보인다. 발표 중간중간에 ‘큰 모델을 갖는게 학습도, 성능에서도 오히려 더 효율적이더라’ 라는 식의 얘기를 반복하는것으로 봐서, 이번 발표는 큰 모델인 HyperCLOVA 에 대한 대대적인 광고와 함께 기술 과시, 기술 제휴처 모집, 채용 홍보 등의 다양한 목적들을 이루기 위한 것으로 이해됐다. 봇빌더의 형태를 한참 넘어선 자연어 기반(프롬프트 기반)의 모델 학습을 가능하게 하는 HyperCLOVA studio 가 상당히 인상깊었다.
개인적으로 백엔드 엔지니어인 필자에겐 마지막의 Service Infrastructure 관련 발표가 제일 흥미롭고 관심있는 부분이었고, 어떤 포인트들에 대한 개발을 진행했는지에 대한 개괄적인 얘기만 해서 정확한 내용을 파악하긴 힘들지만, 그래도 간접적으로나마 많은 시행착오를 겪었겠거니 하고 생각할 수 있었다.
important-note
- 아래의 이미지들은 naver ai now 의 발표 영상에서 캡처한 내용이다.
- 아래의 내용들은 대부분 naver ai now 의 발표 내용의 정리이고, 필자의 감상이 일부 포함되어있다.
contents
- trustworthy 한 model develop
- 빅 모델을 이용한 방식
- 모델의 일반화, 확장, 모델의 플랫폼화
- AI 모델 파라미터 수가 높아지면, 성능이 좋아진다는.. 다소 당연한 이야기
- Big AI
새로운 ai 방법론의. 3가지 요소
- super computing infra
- data
- ai specialist
5600억 토큰의 한국어 데이터
- GPT 학습에 사용된 한국어의 6500배
데이터를 레이블링 없이, 최대한 비지도 학습시킬 수 있는 방법을 많이 연구했다고 한다.
큰 모델이 더 경제적이고 효율적일수있다는 연구
사용처
- 자연스러운 대화
- 창작을 도와주는 글쓰기
- 정보 요약
- 데이터 생성
- 등등..
앞으로 multi-modal 지원할 예정

슈퍼 컴퓨팅 인프라
- 고성능 병렬 gpu 클러스터
- 초 저지연 고대역폭 네트워크
- 병렬 아키텍처 스토리지
대용량 데이터
데이터 구축 조건
- 다양한 내용
- 범용의 구성
- 양질의 정보
- 충분한 크기
Hyper Clova 의 한국어 모델
한국어 모델 만든 이유: GPT-3 는 영어 전용 모델에 가깝다.
HyperCLOVA 가 한국어를 읽는 방법(tokenization)
HyperCLOVA의 언어모델은 학습용 말뭉치의 1%로부터 학습된 Morpheme-Aware Byte-Level BPE Tokenizer 로 문장을 처리함
HyperCLOVA 의 한국어 능력 평가: 지표
생성문장과 레퍼런스 문장 간의 유사성이 문장 품질을 보장하지 않는다. > 더이상 BLEU 와 같은 품질 지표를 사용하기엔 어렵다.
서로 다른 설정(어휘집합과 같은)에서 학습한 모델들을 Perplexity(PPL) 로 비교하는게 부적절하다.
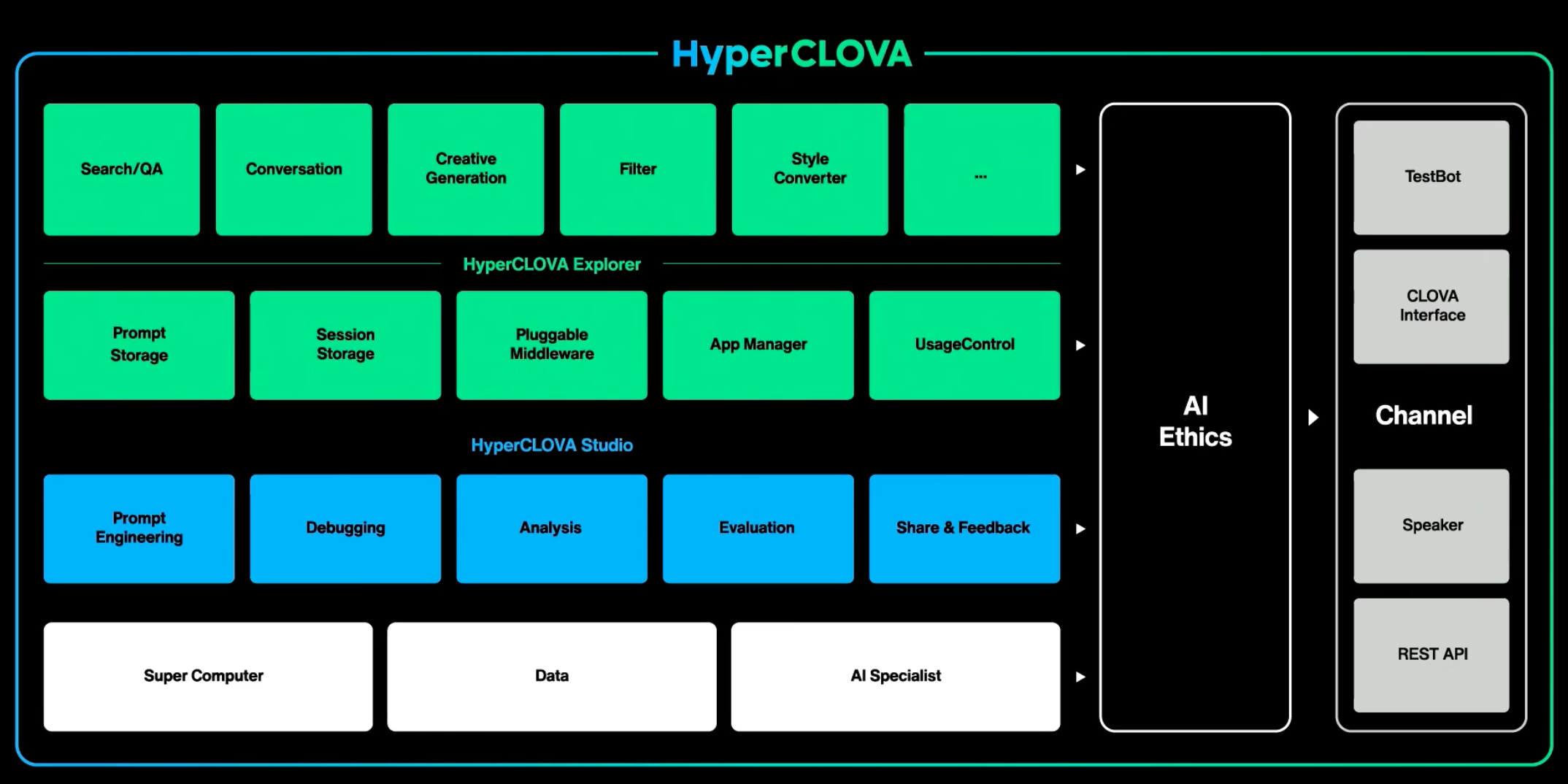
HyperCLOVA studio
- 몇가지 curation 에서 모델이 개발되는 데모
HyperCLOVA 활용 1 | 검색 어플리케이션
- 검색결과 없는 Null-query 재작성
- 쇼핑 리뷰 요약
- 질의응답 태스크
HyperCLOVA 활용 2 | AI 어시스턴트
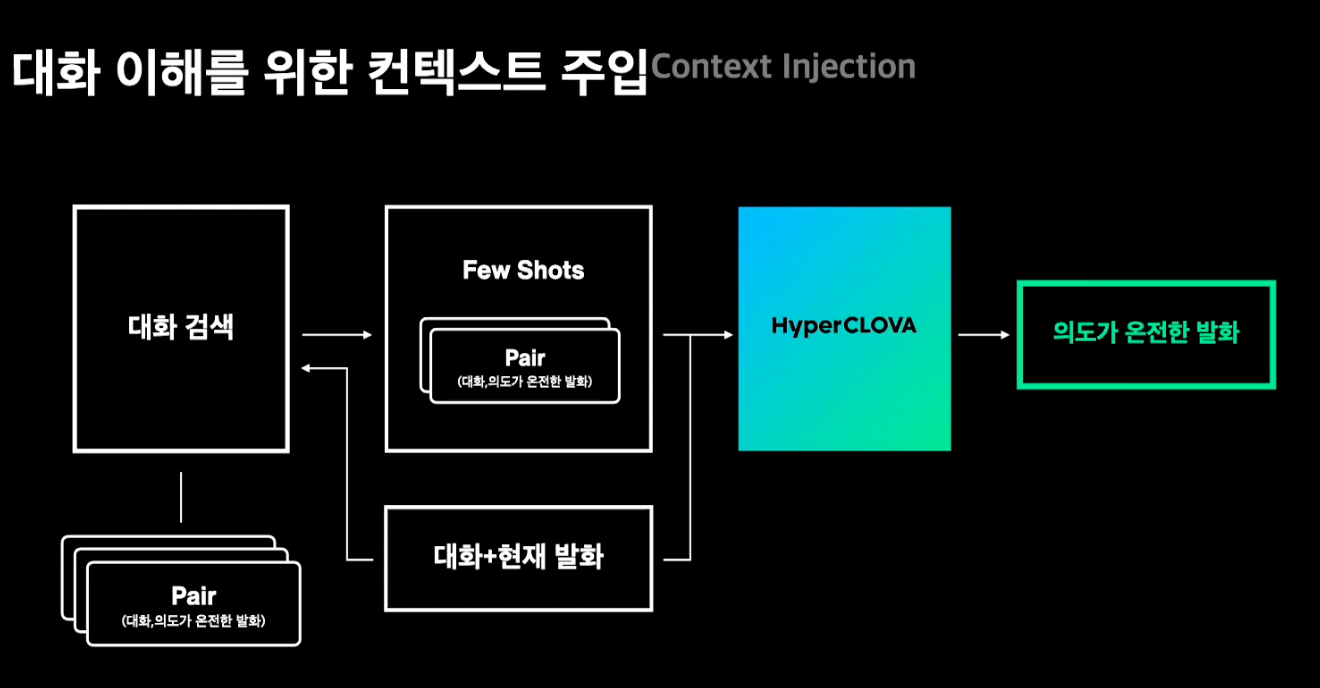
- 대화 이해
컨텍스트 주입
- 대용어 해소, 대화 상태 추척 기술 필요 (‘그때’, ‘그 다음’)
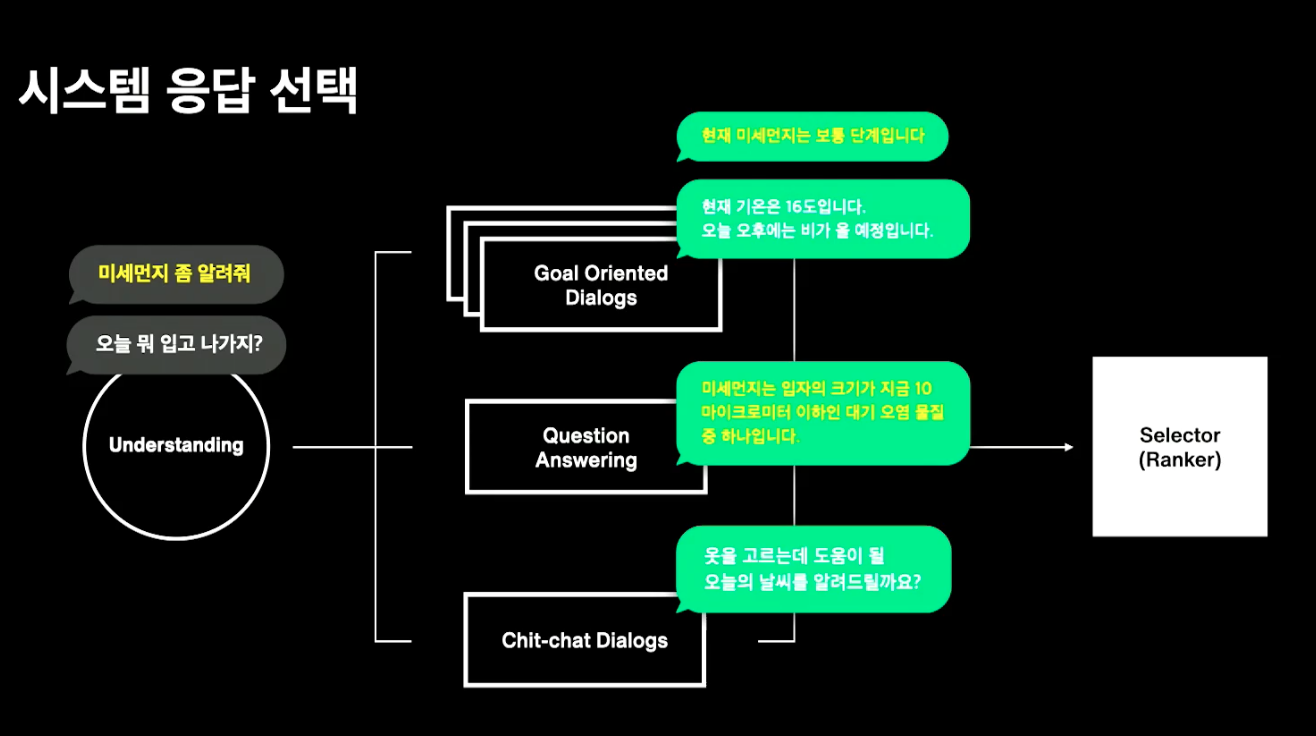
- 시스템 응답 선택
시멘틱 검색을 이용한 응답 선택
- 시스템 응답 생성
응답생성 조율 방법
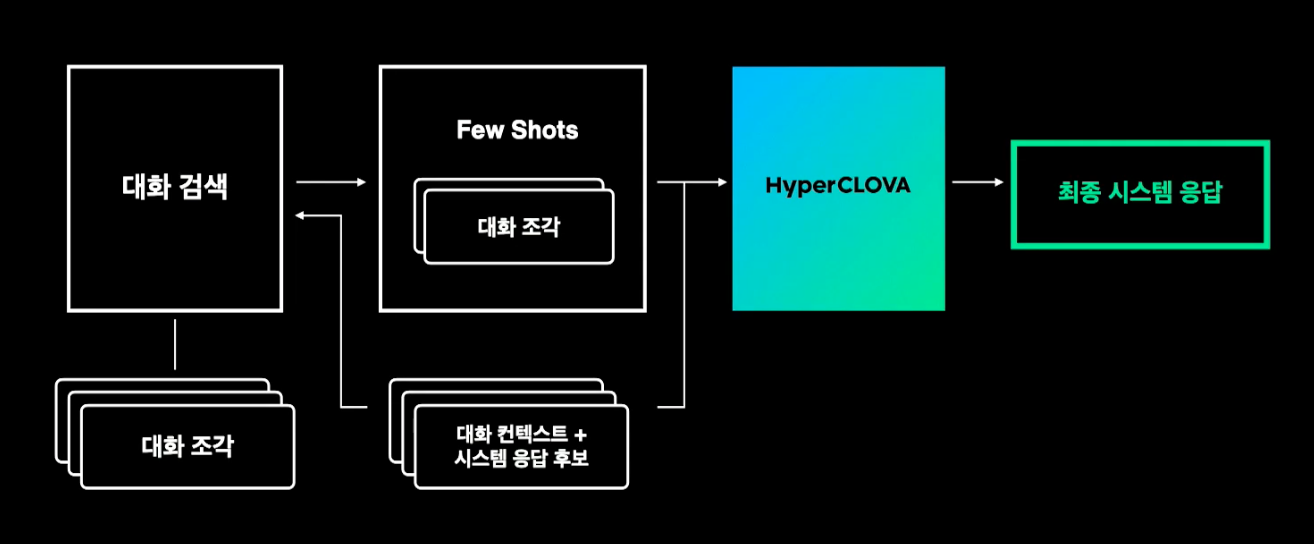
HyperCLOVA 활용 3 | 대화
prompt(prompt control unit) 에 추가된 내용으로 few-shot-learning 을 이용한 호출.
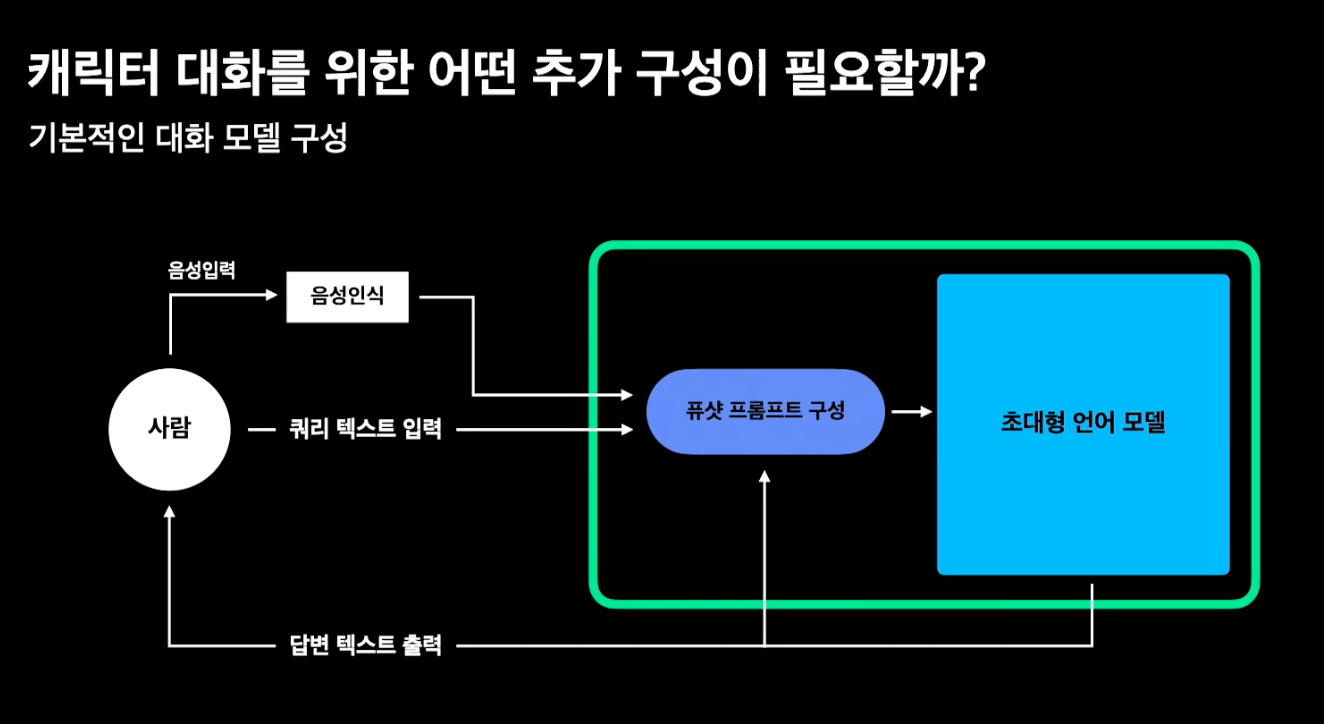
HyperCLOVA 활용 4 | 증강
- In context learning, calibrate before use
극소량 파인튜닝을 통한 성능개선: prefix-tuning, p-tuning
- 무거운 모델에 직접 inference 하는게 아닌 방식으로 hyperClova 를 사용가능해짐
HyperMix
- 파인튜닝, 프롬프트 기반 방법의 대안으로 데이터 증강 구조 제안

HyperCLOVA 의 조율
프롬프트 튜닝, 프롬프트 엔지니어링에 대한 예시
- 이산환경
- 연속환경
Service Infrastructure
모델 병합:
- 단일 GPU 인퍼런스가 불가능한 모델이 대부분이라, 모델 병합이 필수
멀티노드서빙 (싱글노드에서 서빙이 불가능할 정도로 많은 VRAM 요구되는경우)
모델을 빠르게 업로드하기 위해, 병렬 업로드 처리함
모델과 인퍼런스 이미지를 분리해서 볼륨으로 마운트 하는 방법을 채택함
- 모델이 너무 크기 때문
- 코드의 변경으로 모델 포함 이미지를 다시 만드는건 비현실적
- 이미지 빌드 없이 롤링 업데이트도 쉬워짐

다이나믹 배칭
- 배치처리를 위한 배치키 생성, 키를 그룹지어서 처리할 수 있도록 함
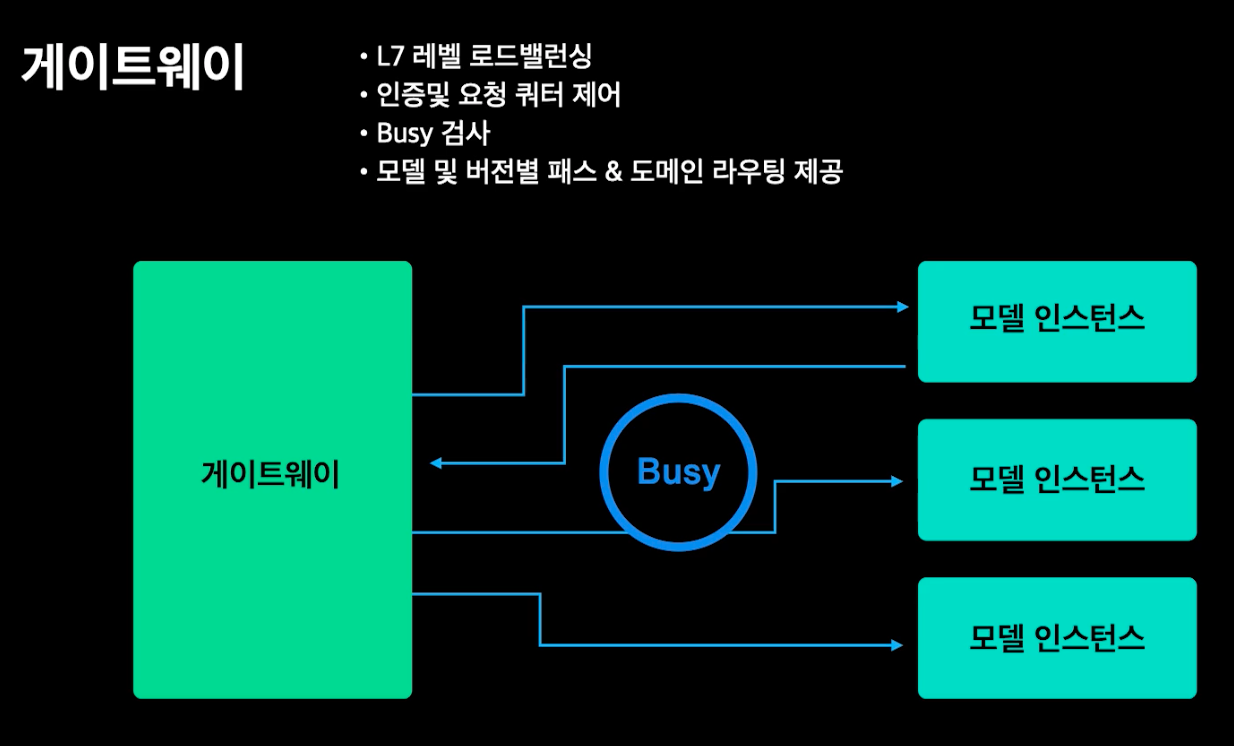
게이트웨이
- L7 레벨 로드밸런서
- 인증, 요청 쿼터 제어
- Busy 검사, 트래픽 분배/ 재시도
- 모델 배포시 버전별 path, domain routing 기능 제공
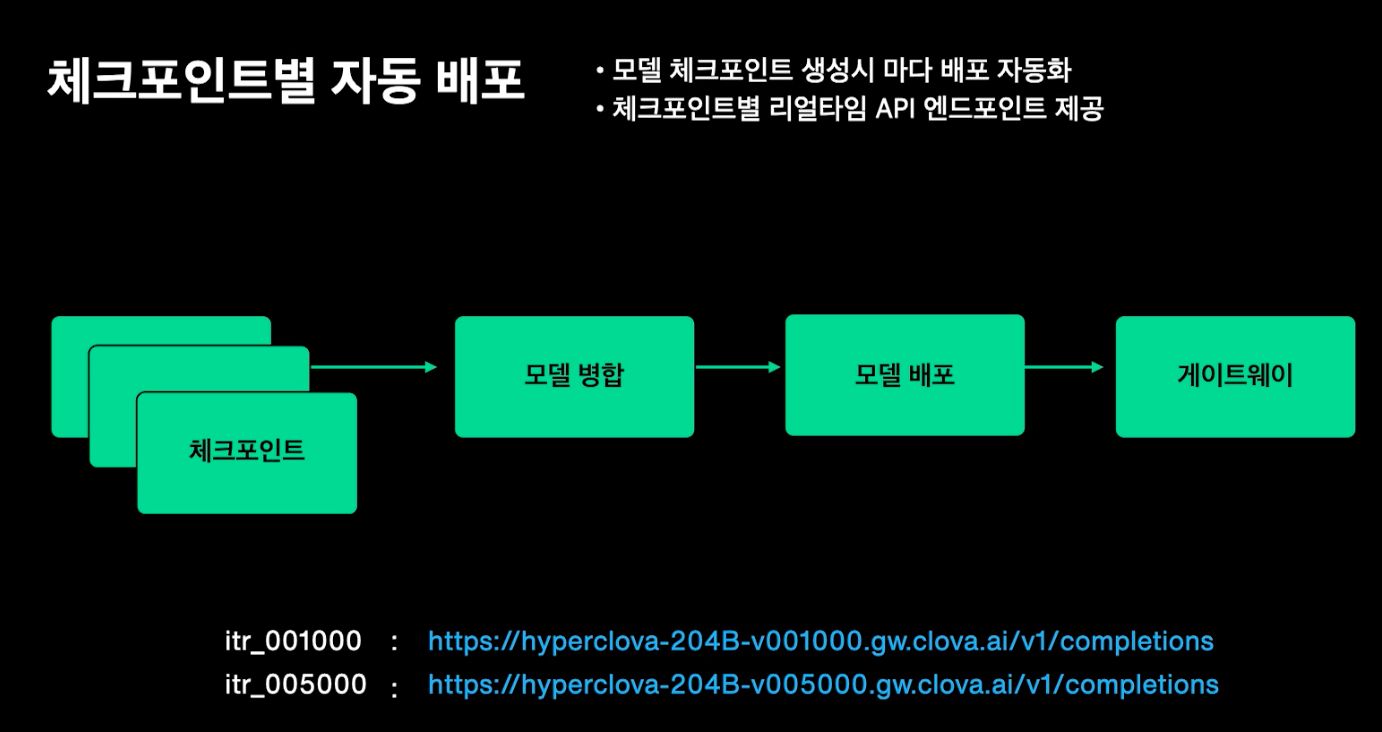
체크포인트별 자동 배포
- 모델 체크포인트 생성시 마다 배포 자동화
- 체크포인트별 리얼타임 API 엔드포인트 제공
- 이 엔드포인트로 바꿔가면서 모델 테스트 가능함
AB 테스트 / 쉐도잉
모델 성능에 대한 불확실성이 있어서, 대표로 사용하는 모델 엔드포인트에서 여러개의 체크포인트를 백엔드로 트래픽 나눠서 보낼 수 있도록
다이나믹 설정(웨이트 조절 및 카나리 배포 가능함)
신규 인퍼런스 구현체를 테스트하기위한 쉐도잉(본 모델에 100% 트래픽 받으면서, 실제 트래픽을 가져와서 테스트를 진행하는 방법론)
멀티노드 인퍼런스, k8s 기반 서빙 오퍼레이터 개발, hyperclova app 플랫폼화 계획이 있음
Comments powered by Disqus.