OOM 이 발생하는 application 개선과정
Introduction
protobuf 로 serialize 된 input 파일을 읽어서 parquet 로 변환하는 간단한 application 의 memory 사용량이 높은지, 작업을 돌리면 꽤나 높은 memory 를 할당했음에도 불구하고 심심찮게 OOM (Out Of Memory) 으로 인해 작업이 kill 되는 현상이 있었다. 1차적으로는 이러한 OOM 을 방지하여 작업의 안정성을 높이고 (번거롭게 실패한 작업들만 따로 실행하는 것을 방지한다), 2차적으로는 작업의 전반적인 메모리 사용량을 줄여보는 작업을 하게 되었다.
Contents
OOM 이 일어나지 않게하려면, 얼마나 많은 메모리가 필요한걸까?
우선 Input file 의 크기가 커질수록 memory 사용량도 늘어나지 않을까? 하는 가정을 하였고 가장 큰 파일을 찾아 동일한 환경을 구성하였다. 흥미로운 것은, protobuf 의 압축률이 큰 탓(덕)인지 1.7GB 의 input 을 읽어들이는데 12GiB 정도의 메모리를 사용하고 있었다. 예상보다 많은 메모리 사용량에 당황스러웠다.
Pprof 를 이용한 메모리 사용량 검토
go tool 중에 pprof 가 있다. main 함수 시작부분에 아래와 같이 defer function 을 작성하여 프로세스가 종료되기 전에 HeapProfile 을 작성하도록 하였다.
1
2
3
4
5
6
7
8
9
10
11
defer func() {
f, err := os.Create("/path/to/mem_usage.memout")
if err != nil {
log.Fatal("could not create memory profile: ", err)
}
defer f.Close() // error handling omitted for example
if err := pprof.WriteHeapProfile(f); err != nil {
log.Fatal("could not write memory profile: ", err)
}
}()
이렇게 작성한 memout 파일은 go tool pprof -http=:8082 mem_usage.memout 과 같이 web-based 로 보기 편하게 제공된다. 여기에 다양한 option 들이 있는데 각각의 의미는 다음과 같다.
https://www.freecodecamp.org/news/how-i-investigated-memory-leaks-in-go-using-pprof-on-a-large-codebase-4bec4325e192/
생각보다 이 툴(memory profiling)의 도움을 받지는 못했는데 결론부터 말하자면 메모리 사용량에 큰 문제는 memory leak 의 측면이라기 보다는 go-runtime 이 OS 에게 할당받은 메모리 중에서 충분히 OS 로 반환되어도 괜찮을 상황에 garbage collector 가 동작되지 못했고 그러다보니 기존에 할당받은 메모리에 추가로 메모리를 할당받아 container 에 최대한 할당할 수 있었던 memory limit 을 넘어가게 되어 OOM 이 발생했다. 이 부분을 발견하는데는 아래에 언급할 golang 의 runtime.Memstats struct 를 이용한 다소 많은 수작업이 필요했던 line by line 으로 현재 memory 상태를 print 해보는 방식이었다.
동작 분석
메모리 사용량 개선작업을 진행한 app 은 크게 2가지 단계로 동작한다. 1) Input 을 읽어서 메모리에 올린다. 2) 읽은 파일을 가공해서 DB 에 upload 한다.
1) 단계를 개선하는 방법으로는 한번에 모든 Input 을 읽어 메모리에 올리기 보다는, 일부만 읽는 방법이 있겠다. 그런데 대상 app 에서 지원하는 input 은 protobuf 포맷이었다. Protobuf 는 현재(2022년 4월) 기준까지 deserialize 하는데에 streaming API 를 제공하지 않고있다. 조금 정리하자면, 여러 line 의 json으로 구성되어있는 jsonl 포맷 같은경우 line by line 으로 읽어서, 온전한 json 형태를 만나면, deserialize(혹은 unmarshal) 을 멈추고 다음 json 을 처리할 수 있지만, protobuf 의 경우 모든 파일을 다 읽어내기 전까지는 처리가 불가능하다. 결국, 파일을 읽어서 크기를 줄이는 단순한 방식으로 접근을 했으나 이것도 문제가 있는데 애초에 큰 파일을 읽어내기 위해서 많은 메모리 소모는 필연적인것이다. 예를들어 아무리 읽는데 16GiB 의 메모리가 필요한 큰 파일을 읽어서 작게 나눴다고 해도, 별도의 go-runtime 이 실행하는 process 로 처리하지 않는 이상 적어도 한 번 이상의 16GiB 메모리가 필요하다. 결론적으로, 다른 프로세스로 나누기는 다소 번거롭기도 하고, 그래도 짧게라도 큰 메모리를 사용한 이후에 빠르게 메모리를 반환하여 이후로는 적은 메모리 사용으로 안정적으로 app 을 실행하려는 방식을 택하게 되었다.
memory profiling 을 해봤을때 2) 단계 보다는 1) 단계가 더 큰 병목으로 판단되었기 때문에 큰 변경을 하진 않았다.
runtime.Memstats 를 이용한 특정 시점의 메모리 사용량 분석
아래와 같이 runtime.MemStats struct 를 runtime.ReadMemStats 를 이용해서 매번 읽어와서 현재 memory 상태를 확인해 볼 수 있다.
https://golangcode.com/print-the-current-memory-usage/
여기서 Alloc 은 현재 heap memory allocation 이라고 생각하면 되고, TotalAlloc 은 alloc 됐던 내용의 누적이고, Sys 는 go-runtime 이 OS 에 할당받은 메모리이다.
큰 protobuf 파일을 읽는데만 아래와 같이 큰 memory 가 필요했다. 읽는 과정에서 이미 30번의 GC 가 일어난 것을 확인할 수 있다.
1
2
3
4
5
6
## Before Reading big protobuf file
Alloc = 5 MiB TotalAlloc = 8 MiB Sys = 23 MiB NumGC = 3
## After Reading big protobuf file
Alloc = 11324 MiB TotalAlloc = 18948 MiB Sys = 11996 MiB NumGC = 33
## After Running GC
Alloc = 5 MiB TotalAlloc = ... MiB Sys = 11996 MiB NumGC = 34
이미 1.7GB 의 .pb 파일을 읽어내는데 11GiB 정도의 메모리 할당이 있는데, 여기서 추가로 작업이 진행될때, Sys 가 늘어나면서 container 의 memory limit 을 넘어가는 일이 발생하였다.
그래서 택한 방식은 최대한 코드적으로 메모리를 잘 반환할 수 있도록 작성한 후에, 강제로 GC 를 실행시키는 것이다. golang 에서 GC 는 강제로 크게 2가지 방법으로 실행시킬 수 있는데 하나는 runtime.GC() 이고, 다른 하나는 debug.FreeOSMemory() 이다. 각각의 주석들을 아래에 붙여넣었는데, GC() 는 예상대로 GC 를 실행시키는 것이고, FreeOSMemory() 는 GC 실행 후에 OS 에 최대한 메모리를 반환하는 과정을 포함한다는데 실험을 해보니 예상대로 진행되진 않았다. 이는 golang 에서는 memory 관리를 직접적으로 하진 못하게 하려는 설계가 바탕이 되기때문인것 같다.
1
2
3
4
5
6
7
8
// GC runs a garbage collection and blocks the caller until the
// garbage collection is complete. It may also block the entire
// program.
// FreeOSMemory forces a garbage collection followed by an
// attempt to return as much memory to the operating system
// as possible. (Even if this is not called, the runtime gradually
// returns memory to the operating system in a background task.)
주의 사항으로는 이 app 은 실시간으로 사용자의 트래픽을 받거나 하는 용도가 아닌 ETL 에 해당하는 BatchJob 의 성격을 갖고있기 때문에 runtime.GC() 를 실행하며 생기는 성능적 병목에 대해서는 크게 고려할 필요가 없었다. 실제로 디스코드에서 GC 가 발생할때마다 발생하는 성능 병목을 해결하지 못해 golang 에서 rust 로 넘어갔다는 글도 읽은적이 있다. 물론, 이런 이유뿐만은 아니었을 것 같다.
GC 를 실행해도 Sys 가 반환되지 않는 이유
위에서 runtime.GC() 를 실행했을때 Alloc 은 만족할만큼 내려갔는데, Sys 값은 반환되지 않았다. 물론 그래도 소정의 목적은 달성할 수 있었는데, 이미 Alloc 이 많이 내려가있었기 때문에 추가로 메모리가 필요한 경우에 굳이 Sys 의 크기를 늘리면서 메모리를 할당하는게 아니라 이미 충분히 확보해놓은 Sys 에서 할당이 가능해서 OOM 을 만나진 않게되었다.
분명 GC 를 통해서 Alloc 은 유의미하게 줄어들었고, 왜 Sys 는 반환되지 않는것인가 하는 내용을 구글링을 좀 해봤는데 명확하게 명시되어있는 것은 찾지 못했고, 여러 포스팅, 스택오버플로 답변들에서 시간이 흐른 뒤에 결국에는 반환이 되겠지만, go-runtime 이 메모리를 바로 반환을 하지 않는다고 한다. 실제로 메모리 사용량을 그래프화 해보니 예상치 못한 어느 시점에 메모리 사용량이 줄어드는것을 확인할 수 있었다.
결과
가장 큰 변경은 위에서 언급했듯 큰 파일을 읽어들이고 GC 를 강제로 실행시켜서 allocation 을 줄여서 OS로 부터 추가로 메모리를 할당받지 않도록 하였다. 그 결과 그래프는 아래와 같다.
메모리사용량이 꾸준히 올라가고는, 해소되지 않고 24GiB 정도로 꾸준히 유지되다가 종료되는 그래프를 확인할 수 있다.
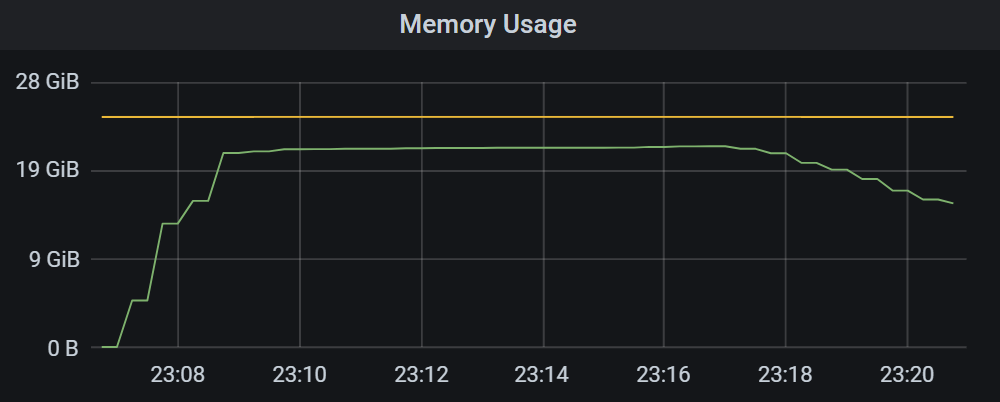
12GiB 정도로 처음에 피크를 치고 이후로 줄어들어 2-3GiB 정도로 낮게 유지되는것을 확인할 수 있다. 만약에 별도의 container 를 이용해서 파일 크기를 줄인다면 전반부의 12GiB 와 같이 큰 메모리 사용량이 필요하지 않게 될 것이고, 훨씬 더 효율적인 메모리 사용이 가능할 것으로 예상된다.

Appendix
Protobuf 는 streaming API 를 제공하지 않고 있다.
Protobuf 문서중에 Streaming Multiple Messages, Large Data Sets 부분을 보면, 큰 규모의 데이터를 다룰때는 적합하지 않다(한 protobuf struct 가 엄청나게 큰 경우를 의미할것이다. 조각으로 나눴을때 간결하게 분해가 된다면 왠만하면 문제가 되진 않는다고 한다)
Streaming Multiple Messages:- PB 는 self-delimiting (json 처럼 한 struct 가 온전히 끝났는지 아닌지를 판단하는것) 하지 않기 때문에, parser 는 확인할 수 없다. size 를 알고있다면 message 의 size 만큼 읽어서 처리하라고 한다.
gRPC 시작에서 운영까지(by 카순 인드라시리, 다네쉬 쿠루푸)116p 에 따르면 아래와 같다.
1
Protobuf 메세지는 태그, 값 으로 구성되어있고, 이 중 태그는 필드 인덱스와 와이어타입으로 구분된다. 필드 인덱스는 프로토 파일에서 메세지를 정의할 때 각 메세지 필드에 할당된 고유 번호, 와이어 타입은 필드가 가질 수 있는 데이터 타입인 필드 타입을 기반으로 하는데, 값의 길이를 찾기 위한 정보를 제공한다.
위 내용을 바탕으로 굳이 개발한다면 streaming API 구현이 가능할 것 같고, 실제로 protobuf github 에 가보면 해당 논의가 오래전부터 되고 있었지만 진행된 내용은 없고, 일단은 감수하기로 한다. 아래는 proto message 구성의 예시이다.
https://developers.google.com/protocol-buffers/docs/encoding
1 2 3 4 5
22 // key (field number 4, wire type 2) 06 // payload size (6 bytes) 03 // first element (varint 3) 8E 02 // second element (varint 270) 9E A7 05 // third element (varint 86942)
- PB 는 self-delimiting (json 처럼 한 struct 가 온전히 끝났는지 아닌지를 판단하는것) 하지 않기 때문에, parser 는 확인할 수 없다. size 를 알고있다면 message 의 size 만큼 읽어서 처리하라고 한다.
Large Data Sets:- PB 는 큰 메세지를 처리하기 위해 만들어진게 아니다. 각각 1MB 보다 큰 메세지를 다룬다면, 다른방법을 생각하라.
- 큰 dataset 에서 각각의 메세지를 처리하는데는 좋다.
1 2 3 4 5
If you want to write multiple messages to a single file or stream, it is up to you to keep track of where one message ends and the next begins. The Protocol Buffer wire format is not self-delimiting, so protocol buffer parsers cannot determine where a message ends on their own. The easiest way to solve this problem is to write the size of each message before you write the message itself. When you read the messages back in, you read the size, then read the bytes into a separate buffer, then parse from that buffer. (If you want to avoid copying bytes to a separate buffer, check out the CodedInputStream class (in both C++ and Java) which can be told to limit reads to a certain number of bytes.) Protocol Buffers are not designed to handle large messages. As a general rule of thumb, if you are dealing in messages larger than a megabyte each, it may be time to consider an alternate strategy. That said, Protocol Buffers are great for handling individual messages within a large data set. (...중략)
Comments powered by Disqus.